9.1 Human error
|
Previous
Chapter 8: Social implications of computer networks
|
Next
Chapter 10: Social issues and online protection
|

 CHAPTER OVERVIEW
CHAPTER OVERVIEW
| Unit 9.1 | Human error |
| Unit 9.2 | Verification and validation of data |
| Unit 9.3 | Software bugs |
| Unit 9.4 | Hardware failure |
 By the end of this chapter, you will be able to:
By the end of this chapter, you will be able to:
- Discuss the effects of computer and human error on data accuracy
- Describe the garbage in, garbage out (GIGO) principle
- Explain the different data types
- Describe databases
- Describe how data is verified and validated
- Explain what software bugs are
- Define hardware bugs
INTRODUCTION
There are two major factors that can lead to a computer giving you the incorrect results when you enter data, namely human error and bugs. In this chapter, you will learn about the effect that human error has on data input and the accuracy of data, how data is verified and validated, and what software bugs and hardware failure are and how they can affect your computer.
UNIT
9.1 Human error
When data is added manually to a spreadsheet or database, there is room for error.
If the user makes a mistake when entering data, the computer will not be able to pick up on that. This is why we verify and validate data before analysing it.
Human errors can have a significant impact on the validity and accuracy of data. If, for example, a scientist makes a calculation mistake with one entry in a spreadsheet, their results could be off by a large degree. These types of errors can also impact businesses. If an employee enters the price of a product into the database incorrectly, the business may lose money.
THE GIGO PRINCIPLE
GIGO is a concept in data capture and evaluation. It stands for “garbage in, garbage out” and the idea is that if you enter bad data into a system (such as a database or Excel spreadsheet), you will get bad results, or bad input will give you bad output.
UNIT
9.2 Verification and validation of data
DATABASES
As you learned in Term 1, a database is a collection of a large amount of data, which is organised into files called tables.
When discussing data, you need to remember that there are many different types of data. The most common data types, and the ones you are most likely to deal with, are:
- strings
- numeric data
- boolean data
- date and time data.
VERIFICATION AND VALIDATION
In order to get the best results with your data, you will need to make sure that it is accurate. To do this, you will need to first verify the data and then validate it.
Data verification is the process of checking that the data a user has inputted is correct. This can be largely automated, providing someone has set up the rules on the spreadsheet or database. For example, the age range of high-school students is usually 14 to 18 and the spreadsheet can be set up to only accept an age in that range. This is called a range check. This does not always mean that the data will be 100% correct though. If a student is 15 and the user types in 17, the data is still valid in the range, it is just not correct.
Data verification is mainly used when data is entered into a system manually (that is, a human has entered the data into the database or spreadsheet) and there is a possibility that there will be errors in the data.
Data validation, on the other hand, is the process of making sure that the data that has been transferred from one source to the other matches the original data. For example, if you entered the results of a survey into a spreadsheet, you will check that the results you have match the results you entered.
Data validation also checks to see that the data is complete and matches the requirements of the system in which you entered it. In Access, this is done using data validation rules and input masks.
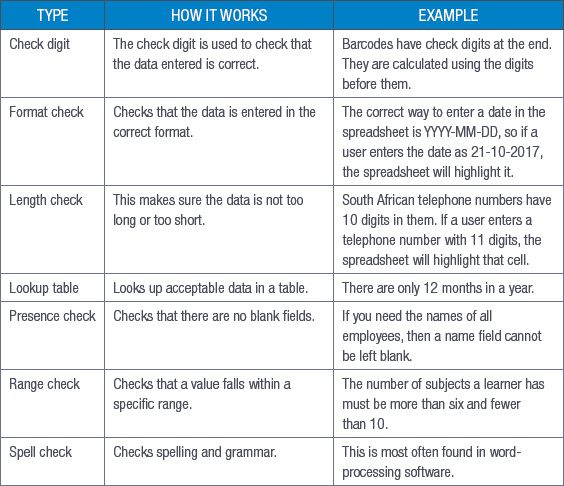
There are several ways to validate data. These are shown in Table 9.1.
Table 9.1: Data validation techniques
UNIT
9.3 Software bugs
A software bug is any error, flaw, failure or fault in a computer program or system that causes it to produce an incorrect or unexpected result or to behave in a way that it was not intended to. This can often cause the program to crash (or stop working) or produce an invalid response.

Did you know
Software bugs are called bugs because the first known programming flaw was caused by a moth that flew into a Harvard Mark II computer in 1946.
Most bugs are caused by human errors made when the source code for the program was written. Some bugs might not have a serious effect on how the program functions and may not be found for a long time, but a program may also be called “buggy” when it has several bugs that make it almost unusable. In some serious cases, programs may have bugs creating security flaws that can lead to a computer being accessed by cyber-criminals.
In the late 1990s, there was widespread fear that when the clock struck midnight on 1 January 2000, the Millennium Bug would cause software systems around the world to collapse, leading to an economic and social shutdown of the world.
This fear was caused because of a problem in the way that some early computers were programmed. They were only designed to handle years that contained two digits, so instead of using 1992, they would use ’92. People started fearing that date-related processes would happen incorrectly for dates and times after 31 December 1999, since there was no way for the computer to tell the difference between the years 1900 and 2000, and that the computers would stop working when the date rolled over.
The idea that a simple change in the date could cause major computer systems to crash caused widespread panic due to the story being covered often in the media and being mentioned in reports on the topic from major corporations.
Needless to say, when the time came, no major computer failures happened. No one is sure if this was because many governments and companies upgraded their software or because there was nothing to fear in the first place.
UNIT
9.4 Hardware failures
Hardware failures are design errors in computer hardware that can cause the hardware to malfunction, fail or be damaged. Some hardware failures can also lead to security flaws in a computer’s system.
FOR ENRICHMENT
Spectre and Meltdown are two hardware failures that affect CPUs built by Intel, AMD and ARM and can allow attackers to potentially steal sensitive data such as banking details and passwords. They were discovered in 2017 by a team from Google’s Project Zero and several academic researchers from around the world.
Their results revealed that these failures had been in the hardware since about 1995 but that they had been previously undetected. They work by exploiting something called speculative execution (or the way a processor knows which task to fetch based on guessing what should happen next in the process and begins fetching instructions from where it thinks the program will go, without knowing for sure). This helps to speed up the computer’s processors.
Combined, these two failures affect nearly every modern computer, including smartphones, tablets and PCs from different vendors running different operating systems. This is because the two failures are a fault in the processors themselves and are not linked to a flaw in any software.
While at the end of 2018 hackers had not released any software that could exploit these failures, computer and smartphone manufacturers advised that users should download and install the latest security fixes as they become available.
REVISION ACTIVITY
QUESTION 1: MULTIPLE CHOICE
1.1Before you analyse data, you must do the following: ______. (1)
A.Spell check it
B.Review it
C.Verify and validate it
D.Organise and simplify it
1.2Information that is incorrectly inputted is referred to as which of the following? (1)
A.Human error
B.Transcription error
C.Transposition error
D.Troubleshooting error
1.3Which of the following is an example of a transposition error? (1)
A.Accidentally deleting an entry
B.Repeating an entry
C.Making a typo
D.Swapping two entries around
1.4Which of the following is NOT a data type? (1)
A.Numbers
B.Strings
C.Dates and times
D.Characters
1.5What does GIGO stand for? (1)
A.Generated Input Generated Output
B.Good Input Garbage Output
C.Good Input Generates Output
D.Garbage In, Garbage Out
QUESTION 2: TRUE OR FALSE
Write True or False next to the question number. Correct the statement if it is FALSE. Change the underlined word(s) to make the statement TRUE. (You may not simply use the word NOT to change the statement.)
a.When we enter data into a computer, the errors that occur are usually computer-based. (1)
b.Transcription errors are most common with text-based data. (1)
c.Human errors negatively impact the validity and accuracy of data. (1)
d.Entering data correctly leads to incorrect results. (1)
e.Binary code is similar to date and time data. (1)
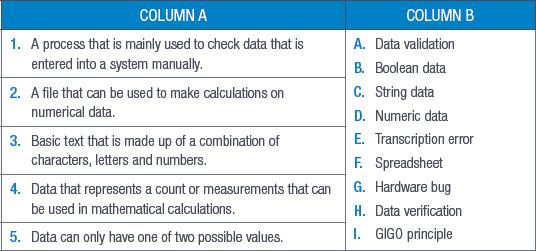
QUESTION 3: MATCHING ITEMS
Choose a term/concept from Column B that matches a description in Column A. Write only the letter next to the question number (e.g. 1J). (5)
QUESTION 4: CATEGORISATION QUESTIONS
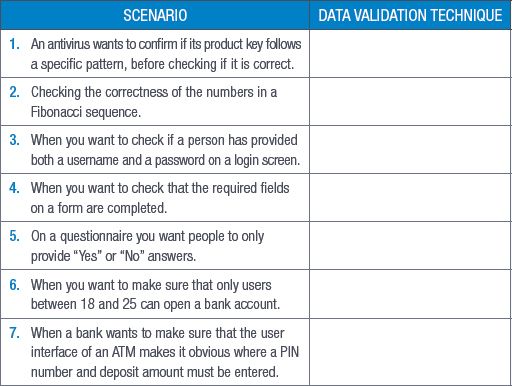
4.1Which data validation technique can be used to validate the data in the following scenarios? (7)
4.2Define a software bug. (2)
4.3Define a hardware bug. (2)
4.4Determine if the following errors are caused by software bugs or hardware bugs. (4)

QUESTION 5: SHORT AND MEDIUM QUESTIONS
5.1What is the main difference between data verification and data validation? (2)
5.2How can you automate the data verification process on a spreadsheet? (2)
5.3Describe the two types of data entry errors and give an example of each. (4)
5.4Maryn’s mouse cannot be detected by her computer when she plugs it in. Mention two things she can do to try and solve this hardware bug. (2)
TOTAL: [40]
AT THE END OF THE CHAPTER

|
Previous
Chapter 8: Social implications of computer networks
|
Table of Contents |
Next
Chapter 10: Social issues and online protection
|