2.1 Characteristics of a good database
|
Previous
Chapter 1: Database management
|
Next
Chapter 3: Hardware
|

 CHAPTER OVERVIEW
CHAPTER OVERVIEW
| Unit 2.1 | Characteristics of a good database |
| Unit 2.2 | Problems with databases |
| Unit 2.3 | How to get rid of anomalies |
 Learning outcomes
Learning outcomes
At the end of this chapter you should be able to:
- provide the characteristics of a good database
- describe the problems with databases
- explain normalisation and the process.
INTRODUCTION
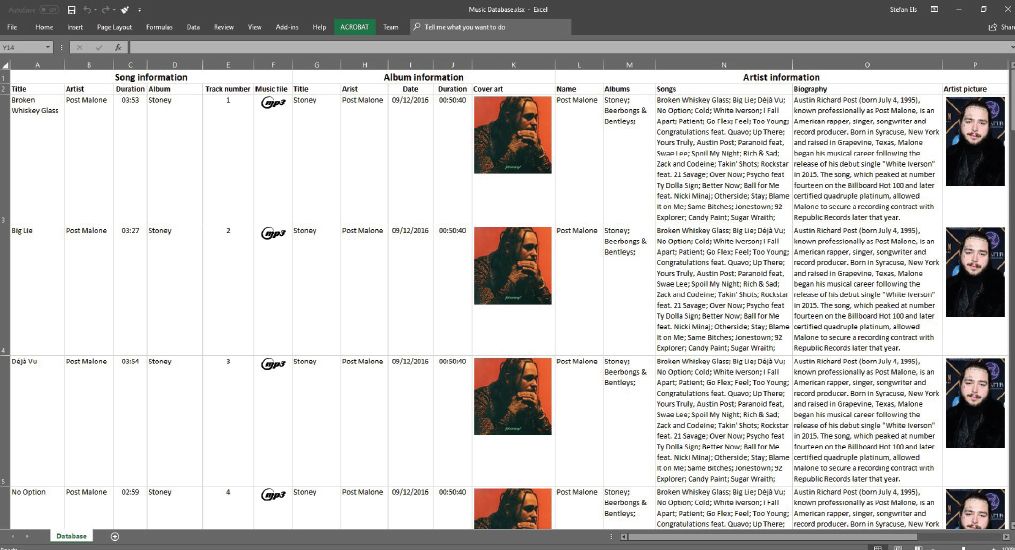
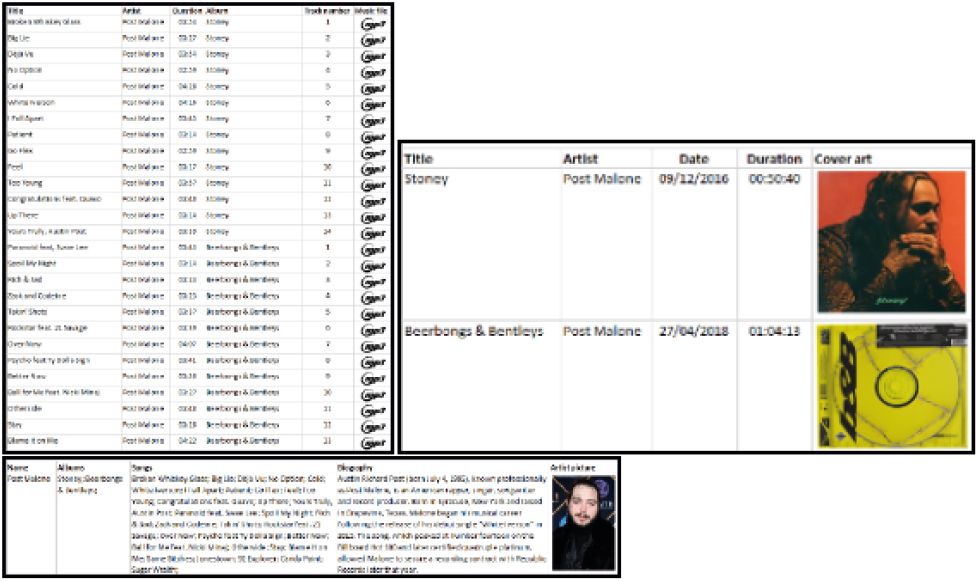
Data is stored in tables in a database. It can be stored in a single table (called a flat database – as shown in Figure 2.1) or in multiple connected tables (called a relational database – as shown in Figure 2.2).

New words
field – a single bit of Information about a person or an item, for example, age
record – a group of related fields about an item or person that is captured in the table
Primary key – a field that holds a unique identifier for each record in the database (Unique means there is only one of its kind)
Each table consists of fields and records. Fields are the categories that you want to record data for. For example, the music table shown above, contains fields like Title, Artist, Duration and Album. Records refer to the actual data being captured, with each record containing the data of a single item. For example, in the Song table, each record represents a single song, with all the information (like artist and duration) related to that song.
Each table may have one compulsory field, called a primary key, which contains a unique identifier for each record in the database. This allows you to refer to a specific record on a table in such a way that it could only refer to one entry. While it is possible to make an existing field of a table a key field, database creators usually create a new field specifically for this purpose. This allows them to make sure that there are no duplicates.
Sometimes there are anomalies with databases, you will learn how to get rid of these anomalies.
In this chapter, you will design and create a relational database. Sometimes there are anomalies with databases, you will learn how to get rid of these and reach normalisation.
DATABASES IN A NUTSHELL
Data, in principal, is stored in 1s and 0s. The computer still needs to know how these 1s and 0s are organised and how they should be interpreted. In order to do this, computers make use of data structures that describe a specific sequence for data to be organised. This allows the computer to understand how the different bits of data are related and to interpret the data correctly.
We know that each letter in the alphabet represents a character. When you add enough characters together, they form a word (like ‘orange’ or ‘love’) that represents a concept. Therefore, allowing communication of useful information between two or more people – even across distances.
In order to communicate data and instructions, data such as numbers, letters, characters, special symbol, sounds/phonics, and images are converted into computer-readable form (binary). Once the processing of this data is complete it is converted into human-readable format, the processed data becomes meaningful information. The information becomes knowledge and can be understood and used by humans for different purposes.
ACTIVITY 2.1 Revision Activity
2.1.1In your own words, explain what a database is and what it can be used for. Provide an example to support your answer.
2.1.2True or False: A data warehouse uses transaction data from various sources and makes analytical use of the data.
2.1.3Fill in the blanks by choosing the correct term from the list below:
[warehouse, tables, current, record, relational, primary, field]
a.Data is stored in ____________ in a database.
b.A single bit of information about an item or person is a ________.
c.When many related fields about an Item are put together the form a ___________.
d.A ___________ key contains unique identifiers for each record in a database.
e.A database is designed to store _____________ transactions whilst a data ______________ stores a large quantity of historical data.
f.A ______________database stores data in multiple tables.
UNIT
2.1 Characteristics of a good database
All good databases should begin with valuable metadata and data. In Chapter 1 we looked at the characteristics of valuable data and how to manage that data. These are illustrated in Figure 2.3 below:
Let’s now look at the characteristics of a good database:
- The database should be strong enough to store all the relevant data and requirements.
- Should be able to relate the tables in the database by means of a relation, for example, an employee works for a department so that employee is related to a particular department. We should be able to define such a relationship between any two entities in the database.
- Multiple users should be able to access the same database, without affecting the other user. For example, several teachers can work on a database to update learners’ marks at the same time. Teachers should also be allowed to update the marks for their subjects, without modifying other subject marks.
- A single database provides different views to different users, it supports multiple views to the user, depending on his role. In a school database, for example, teachers can see the breakdown of learners’ marks; however, parents are only able to see only their child’s report – thus the parents’ access would be read only. At the same time, teachers will have access to all the learners’ information and assessment details with modification rights. All this is able to happen in the same database.
- Data integrity refers to how accurate and consistent the data in a database is. Databases with lots ofmissing information and incorrect information is said to have low data integrity.
- Data independence refers to the separation between data and the application (or applications) in whichit is being used. This allows you to update the data in your application (such as fixing a spelling mistake)without having to recompile the entire application.
- Data Redundancy refers to having the exact same data at different places in the database. Data redundancy Increases the size of the database, creates Integrity problems, decreases efficiency and leads to anomalies. Data should be stored so that It Is not repeated In multiple tables.
- Data security refers to how well the data in the database is protected from crashes, hacks andaccidental deletion.
- Data maintenance refers to monthly, daily or hourly tasks that are run to fix errors within a databaseand prevent anomalies from occurring. Database maintenance not only fixes errors, but it also detects potential errors and prevents future errors from occurring.
There are also many people involved with organising a well-run database. These are:
- the developers, who design and develop the database to suite the needs of an enterprise
- the administrator, who:
- checks the database for its usages
- who is checking it
- provides access to other uses
- provides any other maintenance work required to keep the database up to date
- the end user, who uses the database, for example, teachers or parents.
 Activity 2.1
Activity 2.1
2.1.1Choose a term/concept from COLUMN B that matches a description in COLUMN A. Write only the letter next to the question number (e.g. 5–F).

2.1.2Describe the three types of people who are involved with a database.
2.1.3List the five characteristics of quality data.
2.1.4A school would like to create a database that can:
- keep the parents informed about their child’s academics, assessments and school activities
- help the teachers record work and assessments
- store details of each child and their families.
a. Work in small groups of four or five learners. Discuss each characteristic of a good database and explain these referring to the scenario above.
b. Use a mindmap to present your discussion.
UNIT
2.2 Problems with Databases
If a flat-file database is poorly planned, denormalised and inconsistent, it will create problems when trying to insert, delete or modify the records (tables) in the database. This causes anomalies, which make handling the data increasingly difficult as the database grows. It also makes the data integrity harder to maintain. Trying to make the data consistent once an anomaly occurs can become quite difficult.
There are three types of problems that can occur in databases:
- Insertion anomaly: The database has been created in such a way that required data cannot be added unless another piece of unavailable data is also added. For example, a hospital database that cannot store the details of a new member until that member has been seen by a doctor.
- Deletion anomaly: The legitimate deletion of a record of data can cause the deletion of some required data. For example, deleting some of the patient’s details can remove all the details of the patient from the hospital database.
- Modification anomaly: Incorrect data may have to be changed, which could involve many records having to be changed, leading to the possibility of some changes being made incorrectly.
Example 2.1 Problems that occur in a database
For example, look at the below schema that represents information related to a school:
AccountInfo
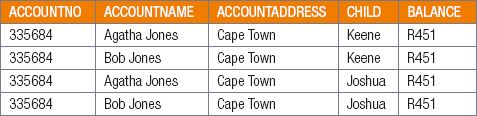
Problems:
- Data redundancy: Data redundancy refers to storing the exact same data at different places in a database. Data redundancy increases the size of your database, creates integrity problems, decreases the efficiency of the database and can lead to database anomalies. Data should be stored in such a way that it should not be repeated in multiple tables. The family can be represented as one unit.
- Update anomaly: Data will be inconsistent if one entity is updated, for example, if the family address changes, the data capturer will need to change all four entities.
- Unable to represent some information: the school cannot keep information about learners who are on the waiting list as they do not have an account with the school.
- Deletion anomaly: closure of the account for one child will remove all data of the second child from the database.
Activity 2.2
2.2.1List the three types of anomalies and provide an example for each one.
2.2.2Look at the below schema that represents information related to a hospital:
AccountInfo
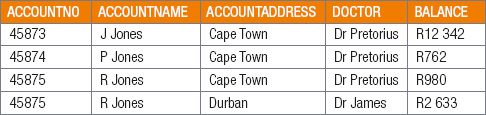
List and explain at least four anomalies with this database.
UNIT
2.3 How to get rid of Anomalies
To prevent anomalies you need to normalise the database by efficiently organising the data in a database.
According to Edgar F Codd, the inventor of relational databases, the goals of normalisation include:
- removing all redundant (or repeated) data from the database
- removing undesirable insertions, updates and deletion dependencies
- reducing the need to restructure the entire database every time new fields are added to it
- making the relationships between tables more useful and understandable.
Normalisation is a systematic approach of decomposing tables to eliminate data redundancy and Insertion, Modification and Deletion Anomalies. The database designer structures the data in a way that eliminates unnecessary duplication(s) and provides a rapid search path to all necessary information. It is a multi-step process that puts data into tabular form, removing duplicated data from the relation tables. This process of specifying and defining tables, keys, columns, and relationships in order to create an efficient database is called normalisation.
Normalisation will reduce the amount of space a database uses and ensure that data is efficiently stored. Without normalisation, database systems can be inaccurate, slow, and inefficient. They might not produce the data that you expect.
In practice this means changing your database so that the following requirements are met:
- each table must have a primary key
- each record should have single valued attributes/columns (atomic)
- there should be no repeating groups of information.
Keys are used to establish and identify relationships between tables and also to uniquely identify any record or row of data inside a table. A key can be a single attribute or a group of attributes (compositeprimary key), where the combination may act as a key. Keys help us to identify any row of data.
When designing a database, the four types of key fields are:
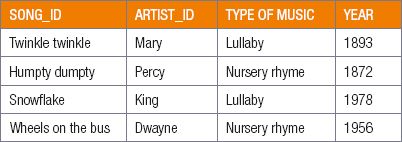
- Primary key: the field selected by the database creator to uniquely identify each record on a table. For example, each song in your music database might have a primary key field called “song_id”.
- Alternative key: a field containing unique values that could be used as the primary key but is not currently set as the primary key, for example, artist_id.
- Foreign key: a field containing values from a different table’s primary key field. Foreign keys are used to show the relationship between different tables. For example, each song in your music database might have a foreign key field called “artist_id” that links the song to a specific artist on an “artists” table.
- Composite key: a combination of more than one field that uniquely identifies each record on a table, for example, song_id and artist_id.
Let’s use this example to understand the four main types of keys:
Normalisation rules are divided into the following normal forms:
FIRST NORMAL FORM (1NF)
For a table to be in the First Normal Form, it should follow the following four rules:
- Each column must have a separate field/attribute. Each column of your table should not contain multiple values. For example, imagine the database for Facebook status updates, specifically the table related to likes. For the records to be indivisible, each like should be stored in a separate record. In this way, each record would either have occurred or not occurred. There is no way to say that only a small part of the like occurred, while a different part did not. However, if all the likes for a status update are stored in a single record, then the record would be divisible, since it would be possible for some of the likes to have occurred while others did not occur.
- Values stored in a column should be of the same kind or type (domain). In each column the values stored must be of the same kind or type.
- All the columns in a table should have unique names. Each column in a table should have a unique name to avoid confusion at the time of retrieving data or performing any other operation on the stored data. For example, specify Child’s name and parent’s name, don’t use ‘Name’.
- The order in which data is stored, does not matter. For example
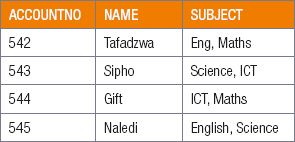
- The table complies to three rules out of the four rules: the column names are unique, the data stored is in the correct order and there are no inter-mixed different types of data in the columns. However, the learners in the table have opted for more than one subject. This data has been stored in the subject names in a single column. As per the 1NF, each column must contain a single value.
SECOND NORMAL FORM (2NF)
For a table to be in the Second Normal Form:
- it should be in the First Normal Form.
- and it should not have Partial Dependency.
This is where an attribute in a table depends on only a part of the primary key and not on the whole key. For example, a table records the primary keys as student_id and the subject_id of each learner. Only the teacher’s name depends on subject. So, the subject_id, and has nothing to do with student_id.
THIRD NORMAL FORM (3NF)
A table is said to be in the Third Normal Form when:
- it is in the Second Normal Form.
- it does not have Transitive Dependency. Transitive Dependency occurs when an attribute/field depends on other attributes/fields rather than depending on the primary key.
This is an indirect relationship between values in the same table.
Activity 2.3
2.3.1Explain why normalisation is important for a database.
2.3.2How can normalisation be reached?
2.3.3List and describe the four types of key fields that can be used in a database.
2.3.4How would you fix the below table to reach 1N?
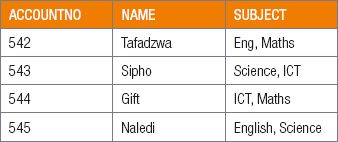
2.3.5Give examples, not mentioned above, of the different key fields.
2.3.6Using the information in the table below, give examples of any two keys.
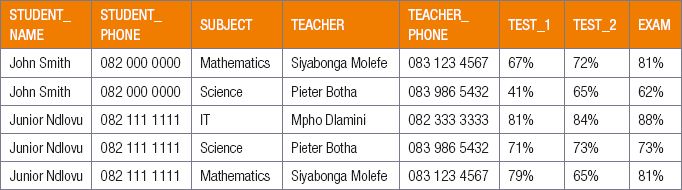
CONSOLIDATION ACTIVITY Chapter 2: Database design concepts
1.Choose the correct answer.
a.Which of the following scenarios does NOT need a database?
A.Storing the credentials of all Gmail accounts.
B.Backing up all the information on your personal computer.
C.Storing all the webpages of a website.
D.Storing all the information about a business’s inventory.
b.Which of the following is a characteristic of a good database?
A.Making copies of data in a database for backup.
B.Keeping the data and application connected and dependant on each other.
C.Preventing errors from occurring in the database.
D.Storing data in different formats.
c.Which of the following is needed to make each record in a database table different?
A.Secondary key
B.Foreign key
C.Primary key
D.Alternative key
2.List the four types of keys used to design a database. Design a table to use as an example.
3.In database design what are the requirements for 1NF, 2NF and 3NF?
|
Previous
Chapter 1: Database management
|
Table of Contents |
Next
Chapter 3: Hardware
|